[성능튜닝] ASH(Active Session History)란?
12bme 2018.01.30 13:41
ASH(Active Session History)
SQL> select * from v$sgastat where name = 'ASH buffers';
POOL NAME BYTES
--------- --------- ---------
shared pool ASH buffers 16252928
- 오라클은 현재 접속해서 활동 중인 Active 세션 정보를 1초에 한번씩 샘플링해서 ASH 버퍼에 저장합니다.
- SGA Shared Pool에 CPU당 2MB의 버퍼를 할당받아 세션 정보를 기록하며, 1시간 혹은 버퍼의 2/3가 찰때마다 디스크로 기록합니다. 즉, AWR에 저장하는 것입니다.
- v$active_session_history 뷰를 이용해 ASH 버퍼에 저장된 세션 히스토리 정보를 조회할 수 있습니다.
select /* 1. 샘플링이 일어난 시간과 샘플 ID */ sample_id, sample_time /* 2. 세션정보, User명, 트랜잭션ID */ , session_id, session_serial#, user_id, xid /* 3. 수행중 SQL 정보 */ , sql_id, sql_child_number, sql_plan_hash_value /* 4. 현재 세션의 상태 정보 'ON CPU' 또는 'WAITING' */ , session_state /* 5. 병렬 Slave 세션일때, 쿼리 코디네이터(QC) 정보를 찾을 수 있게함 */ , qc_instance_id, gc_session_id /* 6. 현재 세션의 진행을 막고 있는(=블로킹) 세션 정보 */ , blocking_session, block_session_serial#, blocking_session_status /* 7. 현재 발생 중인 대기 이벤트 정보 */ , event, event#, seq#, wait_class, wait_time, time_waited /* 8. 현재 발생 중인 대기 이벤트의 파라미터 정보 */ , p1text, p1, p2text, p2, p3text, p3 /* 9. 해당 세션이 현재 참조하고 있는 오브젝트 정보. V$session 뷰에 있는 row_wait_obj#, row_wait_file#, row_wait_block# 컬럼을 가져온 것임 */ , current_obj#, current_file#, current_block# /* 10. 애플리케이션 정보 */ , program, module, action, client_id from V$ACTIVE_SESSION_HISTORY
7과 8번 '대기 이벤트' 정보는 두말할 것도 없고, 6번 '블로킹 세션' 정보와 9번 '현재 액세스 중인 오브젝트' 정보도 매우 유용합니다. 블로킹 세션 정보를 통해 현재 Lock을 발생시킨 세션을 빠릴 찾아 해소할 수 있게 도와줍니다.
오브젝트 정보도 더할 나위 없이 유용하지만 현재 발생 중인 대기 이벤트의 Wait Class가 Application, Concurrency, Cluster, User I/O일 때만 의미있는 값임을 알아야 합니다.
예를 들어, ITL 슬롯 부족?? 때문에 발생하는 enq: TX - allocate ITL entry 대기 이벤트는 Configuration에 속하므로, v$active_session_history 뷰를 조회할 때 함께 출력되는 오브젝트에 Lock이 걸렸다고 판단해서는 안됩니다. 대개 그럴때는 오브젝트 번호가 -1로 출력되지만 직전에 발생한 이벤트의 오브젝트 정보가 계속 남아서 보이는 경우가 있으므로 잘못 해석하지 않도록 주의해야 합니다.
column current_obj# format 99999 heading 'CUR_OBJ#'
column current_file# format 999 heading 'CUR_FIL#'
column current_block# format 999 heading 'CUR_BLK#'
select to_char(sample_time, 'hh24:mi:ss') sample_tm, session_state, event, wait_class, current_obj#, current_file#, current_block#
from v$active_session_history
where session_id = 143
and session_serial# = 9
order by sample_time;
|
SAMPLE_T |
SESSION |
EVENT |
WAIT_CLASS |
CUR_OBJ# |
EUR_FIL# |
CUR_CLK# |
|
15:00:44 |
WAITING |
Enq: TX - row lock contention |
Application |
55765 |
4 |
476 |
|
15:00:45 |
WAITING |
Enq: TX - row lock contention |
Application |
55765 |
4 |
476 |
|
15:00:46 |
WAITING |
Enq: TX - row lock contention |
Application |
55765 |
4 |
476 |
|
15:00:47 |
WAITING |
Enq: TX - row lock contention |
Application |
55765 |
4 |
476 |
|
15:01:36 |
WAITING |
Enq: TX - allocation ITL entry |
Configuration |
-1 |
4 |
476 |
|
15:01:37 |
WAITING |
Enq: TX - allocation ITL entry |
Configuration |
-1 |
4 |
476 |
|
15:01:38 |
WAITING |
Enq: TX - allocation ITL entry |
Configuration |
-1 |
4 |
476 |
|
15:01:39 |
WAITING |
Enq: TX - allocation ITL entry |
Configuration |
-1 |
4 |
476 |
초단위로 쓰기가 발생하는 ASH 버퍼를 읽을 때 래치를 사용한다면 경합이 생길 수 있습니다. 따라서 오라클은 ASH 버퍼를 읽는 세션에 대해서는 래치를 요구하지 않으며 그 때문에 간혹 일관성 없는 잘못된 정보가 나타날 수도 있습니다.
ASH 기능을 이용하면 현재뿐 아니라 과거시점에 발생한 장애 및 성능 저하 원인까지 세션 레벨로 분석할 수 있게 도와줍니다. 오라클 10g부터는 v$active_session_history 정보를 AWR 내에 보관하므로 과거치에 대한 세션 레벨 분석이 가능해졌습니다 (SGA를 DMA방식으로 액세스)
1/10만 샘플링해서 저장(문제가 되는 대기 이벤트는 일정간격을 두고 지속적으로 발생하기 때문에 샘플링된 자료만으로도 원인을 찾는데 큰 지장이 없습니다)
v$active_session_history를 조회했을때 정보가 찾아지지 않는다면 이미 AWR에 쓰여진것으로 dba_hist_active_sess_history 뷰를 조회하면 됩니다.

1. AWR 뷰를 이용해 하루 동안의 이벤트 발생현황을 조회해본다. 그래프는 dba_hist_system_event를 이용해 그린 것인데, 08:15~09:15 구간에서 enq: TM - contention 이벤트가 다량 발생한 것이 환인 되었다.
2. dba_hist_active_sess_history를 조회해서 해당 이벤트를 많이 대기한 세션을 확인한다.
3. 블로킹 세션 정보를 통해 dba_hist_active_sess_history를 다시 조회한다. 블로킹 세션이 찾아지면 해당 세션이 그 시점에 어떤 작업을 수행 중이었는지 확인한다. sql_id를 이용해 그 당시 SQL과 실행계획까지 확인할 수 있다. v$sql과 v$sql_plan까지 AWR에 저장되기 때문이다. 위 사례에서는 블로킹 세션인 Append Mode Insert를 수행하면서 Exclusive 모드 TM Lock에 의한 경합이 발생하고 있었다.
4. program, module, action, client_id 등 애플리케이션 정보를 이용해 관련 프로그램을 찾아 Append 힌트를 제거한다. 그러고 나서, 다른 트랜잭션과 동시에 DML이 발생할 수 있는 상황에서는 insert문에 Append 힌트를 사용해서는 안된다는 사실을 개발팀 전체에 공지한다.
ASH Viewer
ASH Viewer는 오라클 인스턴스 액티브 세션 히스토리 데이터 모니터링을 제공합니다. 링크를 통해 무료로 오픈소스기반 모니터링 툴을 다운받을 수 있습니다.
최근 ASH Viewer를 통해 실시간으로 Oracle 시스템을 모니터링하며 업무 진행하고 있습니다. V$ACTIVE_SESSION_HISTORY 데이터 기반으로 실시간으로 Oracle 시스템 현황을 모니터링 하는 툴인데요. 아직까지는 익숙치 않지만, 기존에 블로그를 통해 학습해왔던 오라클 시스템 튜닝 용어들을 실제 사용과 함께 눈에 익히고 있는 중입니다.
아래는 데모동영상에서 캡쳐한 화면입니다. 실제 Top Activity 화면도 아래와 같았습니다.
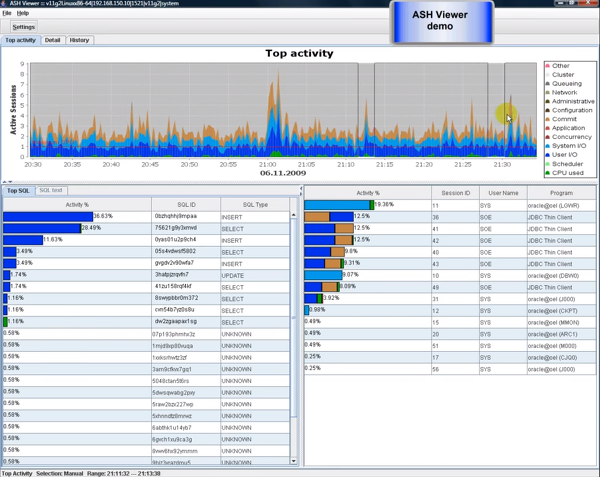
Other, Cluster, Queueing, Network, Administrative, Configuration, Commit, Application, Concurrency, System I/O, User I/O, Scheduler, CPU Used등의 항목을 Activice 세션당 사용률에 따라 아래 그래프처럼 표시됩니다. 보고싶은 시간만큼 그래프를 드래그하면 SQL, Session, Program 상세를 확인할 수 있습니다.
Detail 탭을 누르면 Top Activity 항목에 대한 상세 현황 그래프를 확인할 수 있습니다.
- CPU used (Active Session Waiting)

- Scheduler (Active Session Waiting)
- User I/O (Active Session Waiting)

direct path write temp
direct path read
db file parallel read
direct path read temp
local write wait
db file scattered read
db file sequential read
- System I/O (Active Session Waiting)

log file single write
log archive I/O
db file parallel write
log file parallel write
log file sequential read
control file parallel write
control file sequential read
- Concurrency (Active Session Waiting)
row cache lock
library cache lock
os thread startup
- Application (Active Session Waiting)
enq: R0 - fast object reuse
enq: R0 - fast object reuse
- Commit (Active Session Waiting)

log file sync
- Configuration (Active Session Waiting)
log file switch (check point incomplete)
enq: HW - contention
log buffer space
log file switch completion
- Administrative (Active Session Waiting)
- Network (Active Session Waiting)
SQL*Net more data from client
SQL*Net more data to client
- Queueing (Active Session Waiting)
- Cluster (Active Session Waiting)
gc current grant busy
gc cr block busy
gc cr disk read
gc current request
gc cr request
gc current block 3-way
gc current multi block request
gc current block busy
gc cr multi block request
gc cr block 3-way
gc cr block 2-way
gc current block 2-way
gc cr grant 2-way
- Other (Active Session Waiting)
enq: TT - contention
px deq:L Signal ACK
LGWR wait for redo copy
reliable message
latch: KCL gc element parent latch
gcs log flush sync
enq: FB - contention
enq: WF - contention
null event
CGS wait for IPC msg
DFS lock handle
enq: PS - contention
실행방법: "/bin/java.exe" -Xmx528m -Dswing.defaultlaf=javax.swing.plaf.nimbusLookAndFeel -jar ASH.jar
* swing.defaultlaf 디폴트 Look&Feel 클래스 지정
* 실행방법 옵션 관련 추가 팁
JAVA 기반 어플리케이션을 구동하다보면 OOM(Out Of Memory)관련 에러가 발생하는 경우가 종종있습니다. 이럴 경우, JVM 옵션을 통해 관련 부분을 튜닝할 수 있습니다. 위 실행 방법의 Xmx가 그 옵션 중 하나입니다.

JAVA 메모리 구조
- Heap = Eden + Survivor + Old
- Non-Heap = Perm
GC와 Heap 영역의 기본 동작 원리
- gc는 Eden과 ss1을 클리어하고 여전히 유효한 메모리에 대해서는 ss2로 이동시킵니다.
- 그 다음 gc는 Eden과 ss2을 클리어하고 다시 유효한 메모리에 대해서는 ss1로 이동시킵니다.
메모리는 우선, Heap과 Non-Heap으로 나뉩니다.
- Heap영역: new 연산자로 생성된 객체와 배열을 저장하는 영역으로 GC대상이 되는 영역입니다.
Eden: new키워드를 통해서 객체가 처음 생성되는 공간
Survivor: GC가 수행될때 살아있는 객체는 survivor 영역으로 이동
Old: survivor에서 일정시간 참조되는 객체들이 이동되는 공간
- Non-Heap영역: 스택, 클래스 area, method area 등의 head을 제외한 나머지 영역
Permanent: Class 메타정보, Method 메타정보, Static Object, 상수화된 String Object, Class관련 배열 메타정보, JVM 내부 객체와 최적화컴파일러(JIT) 최적화 정보 등 포함
XX: MaxPerm Size 옵션 값
XX:MaxPerm Size는 hot-deploy가 있을때 메모리 사용량이 점차 증가하는 부분입니다. 가령 서버에서 PermGen OOM 에러 발생시 이부분의 사이즈를 조절해야 합니다.
JVM Option
|
-Xms |
초기 Heap Size (Init, default 64M) |
|
-Xmx |
최대 Heap Size (Max, default 256M) |
|
-XX:PermSize |
초기 PermSize |
|
-XX:MaxPermSize |
최대 PermSize |
|
-XX:NewSize |
최소 new size(객체가 생성되어 저장되는 초기공간의 Size로 Eden+Survivor 영역) |
|
-XX:MaxNewSize |
최대 new Size |
|
-XX:SurvivorRatio |
New/Survivor영역 비율 (n으로 지정시 Eden: Survivor = 1:n) |
|
-XX:NewRatio |
Young Gen과 Old Gen의 비율(n으로 지정시 Young:Old = 1:n) |
|
-XX:+DisableExplicitGC |
System.gc() 콜을 무시 |
|
-XX:+UseConcMarkSweepGC |
표준 gc가 아니나 Perm Gen영역도 gc하는 Concurrent Collector를 사용 |
|
-XX:+CMSPermGenSweepingEnabled |
Perm gen영역도 GC의 대상이 되도록 지정 |
|
-XX:+CMSClassUnloadingEnabled |
클래스 데이터도 GC의 대상이 되도록 지정 |
위에 기본 값을 기준으로 흔하게 일어나는 상황에 대한 조치 방법은 아래와 같습니다.
Hot Deploy 사용으로 재배포가 자주 일어나는 시스템 환경인 경우
1. PermGen 영역의 사이즈를 충분히 늘린다(but 한계 존재)
2. UseConcMarkSweepGC, CMSPermGenSweepingEnabled, CMSClassUnloadingEnabled 등의 옵션으로 PermGen 영역도 GC 수행
OOME, PermGen OOME(Out of Memory Exception) 발생
1. OOME: Xms, Xmx 조정
2. PermGen OOME: XX:PermSize, XX:MaxPermSize 조정
Xmx, Xmx를 동일하게 세팅하는 이유
1. Xms로 init메모리를 잡고, committed 도달할때까지 Used용량이 점차 증가하는데, committed에 도달시 메모리를 추가할 당시 시스템 부하 발생(WAS가 몇 ms가량 멈출 가능성 있음)
2. 메모리 용량은 init < used < committed < max
보통 운영시스템에서 Xms와 Xmx를 동일하게 지정하는 이유는 init와 max사이에서 used 메모리가 committed까지 사용하게 되면, 신규 메모리 공간을 요구하는데 이때 약 1초가량 jvm이 메모리 할당을 멈추는 경우가 생깁니다. 그래서 Xms와 Xmx를 동일하게 주고 메모리를 확보한 상태에서 jvm을 기동시키고는 합니다.
https://sourceforge.net/projects/ashv/
'ORACLE > 공부하기' 카테고리의 다른 글
| Oracle RAC의 Cache Fusion 캐시퓨전(2) (1) | 2024.02.23 |
|---|---|
| Oracle RAC의 Cache Fusion 캐시퓨전(1) (0) | 2024.02.23 |
| undo tablespace full 관련 (0) | 2019.08.24 |
| CRS 설명 (0) | 2019.07.04 |
| OCR & Voting Disk (0) | 2019.07.03 |