오늘은 오라클 RAC 특징에 있어서 가장 중요한 cache fusion에 대해서 알아보겠다. 그러면 그 전에 DB Buffer cache에 대해서 알아야 한다.
Node
하나의 DB에 연결된서버를 의미한다. 2 Node RAC는 2대의 물리적인 서버가 하나의 DB에 연결된 경우이다.
Instance
각각의 Node는 각각의 Instance를 가진다. 하나의 Instance는 여러 Node에 중복 존재할 수 없지만 하나의 Node는 여러개의 Instance로 구성할 수 있다.
SGA
하나의 Instance는 반드시 하나의 SGA를 가지며 SGA는 Shared Pool,DB Buffer Cache, Redo Log Buffer 등으로 구성된다.
Cache Fusion과 DB Buffer Cache
DB Buffer Cache는 유저가 요청한 SQL문을 수행하기 위해서 필요한 Data Block을 Disk로부터 메모리로 올리는(Caching) 하는 영역이다. Cache Fusion에서 DB Buffer Cache가 중요한 이유는 Cache Fusion이 서로 다른 Instance의 DB Buffer Cache에서 Block을 이동시키는 부분에서 발생하기 때문이다.
Cache Fusion
Cache Fusion은 OPS(Oracle Parallel Server)의 Block Transformation의 문제를 극복하기 위해 나타난 아키텍쳐이며 이를 통해 Oracle RAC는 성능적으로 안정성을 갖추게 되었다.
*Block Transformation
특정 Instance에 존재하는 Block을 다른 Instance에서 액세스하기 위해서 해당 블럭을 공유 Storage에 write한 후, 그 Block을 호출한 Instance의 DB Buffer Cache로 캐싱하여 Data Block을 다른 Node로 이동시키는 방식이다.
하지만 각각의 Instance에서 많은 작업이 수행되고, 각각의 Instance 사이에서 이동하는 Block이 많으면 성능 저하가 발생한다. 이 이유로 OPS는 사라지게 되었다.
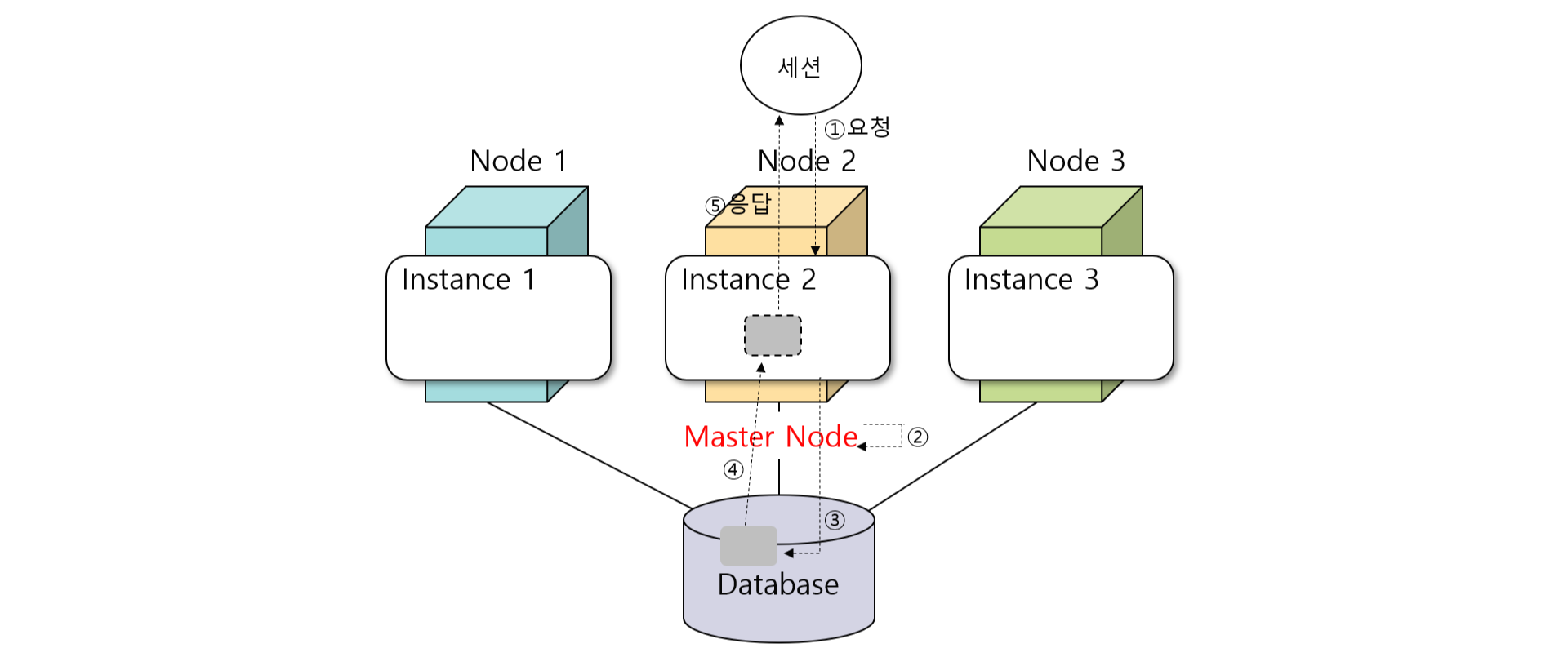
Cache Fusion은 아래와 같은 방식으로 수행된다.
① Instance 2에 접속한 A 프로세스는 Instance 1에 존재하는 1번 Block을 액세스하기 위해 호출한다.
② Instance 1에 존재하는 1번 Block은 Instance 2의 호출에 응답하기 위해 Instance 2의 SGA의 DB Buffer Cache로 이동해야 한다. 이동을 위해 공유 Storage에 존재하는 DB를 이용하지 않고 Instance 사이의 Interconnect를 이용한다.
③ Interconnect를 이용하여 Instance 2로 캐싱된 1번 Block을 A 프로세스가 액세스할 수 있게 된다.
Cache Fusion의 목적
Block이 특정 Node의 DB Buffer Cache에 로드되어 있다면 Disk I/O가 발생하지 않기 때문에 Block 이동을 빠르게 처리할 수 있어서 Oracle RAC의 성능 향상에 가장 중요한 아키텍쳐이다.
Cache Fusion의 구성 요소
•GRD(Global Resource Directory)
RAC에서 Global Resource를 관리한다. Cluster의 동기화를 위해서 Cluster 내의 Resource 정보들(Resource Master, Resource Holder)을 저장한다.
*Resource Master : 특정 Resource의 Master를 지칭한다. 특정 Global Resource는 반드시 하나의 GRD에서 최신 정보를 관리한다.
*Resource Holder : 특정 Resource의 최종 버전을 가지고 있는 Node를 의미한다.
•GCS(Global Cache Service)
Data의 일관성 및 무결성을 유지하는 서비스로, DB Buffer Cache 동기화에 대한 Global 정보를 저장한다. 즉, Block에 대한 Lock 정보를 관리한다.
•GES(Global Enqueue Service)
DB Lock에 대한 정보를 관리하는 서비스로 Block 이외의 Lock 정보를 저장한다. 즉, Enqueue Lock, Library Cache Lock, Row Cache Lock 등의 정보를 관리한다.
SQL> select * from v$sgastat where name = 'ASH buffers';
POOL NAME BYTES
--------- --------- ---------
shared pool ASH buffers 16252928
- 오라클은 현재 접속해서 활동 중인 Active 세션 정보를 1초에 한번씩 샘플링해서 ASH 버퍼에 저장합니다.
- SGA Shared Pool에 CPU당 2MB의 버퍼를 할당받아 세션 정보를 기록하며, 1시간 혹은 버퍼의 2/3가 찰때마다 디스크로 기록합니다. 즉, AWR에 저장하는 것입니다.
- v$active_session_history 뷰를 이용해 ASH 버퍼에 저장된 세션 히스토리 정보를 조회할 수 있습니다.
select /* 1. 샘플링이 일어난 시간과 샘플 ID */ sample_id, sample_time /* 2. 세션정보, User명, 트랜잭션ID */ , session_id, session_serial#, user_id, xid /* 3. 수행중 SQL 정보 */ , sql_id, sql_child_number, sql_plan_hash_value /* 4. 현재 세션의 상태 정보 'ON CPU' 또는 'WAITING' */ , session_state /* 5. 병렬 Slave 세션일때, 쿼리 코디네이터(QC) 정보를 찾을 수 있게함 */ , qc_instance_id, gc_session_id /* 6. 현재 세션의 진행을 막고 있는(=블로킹) 세션 정보 */ , blocking_session, block_session_serial#, blocking_session_status /* 7. 현재 발생 중인 대기 이벤트 정보 */ , event, event#, seq#, wait_class, wait_time, time_waited /* 8. 현재 발생 중인 대기 이벤트의 파라미터 정보 */ , p1text, p1, p2text, p2, p3text, p3 /* 9. 해당 세션이 현재 참조하고 있는 오브젝트 정보. V$session 뷰에 있는 row_wait_obj#, row_wait_file#, row_wait_block# 컬럼을 가져온 것임 */ , current_obj#, current_file#, current_block# /* 10. 애플리케이션 정보 */ , program, module, action, client_id from V$ACTIVE_SESSION_HISTORY
7과 8번 '대기 이벤트' 정보는 두말할 것도 없고, 6번 '블로킹 세션' 정보와 9번 '현재 액세스 중인 오브젝트' 정보도 매우 유용합니다.블로킹 세션 정보를 통해 현재 Lock을 발생시킨 세션을 빠릴 찾아 해소할 수 있게 도와줍니다.
오브젝트 정보도 더할 나위 없이 유용하지만현재 발생 중인 대기 이벤트의 Wait Class가 Application, Concurrency, Cluster, User I/O일 때만 의미있는 값임을 알아야 합니다.
예를 들어, ITL 슬롯 부족?? 때문에 발생하는 enq: TX - allocate ITL entry 대기 이벤트는 Configuration에 속하므로, v$active_session_history 뷰를 조회할 때 함께 출력되는 오브젝트에 Lock이 걸렸다고 판단해서는 안됩니다.대개 그럴때는 오브젝트 번호가 -1로 출력되지만 직전에 발생한 이벤트의 오브젝트 정보가 계속 남아서 보이는 경우가 있으므로 잘못 해석하지 않도록 주의해야 합니다.
column current_obj# format 99999 heading 'CUR_OBJ#'
column current_file# format 999 heading 'CUR_FIL#'
column current_block# format 999 heading 'CUR_BLK#'
초단위로 쓰기가 발생하는 ASH 버퍼를 읽을 때 래치를 사용한다면 경합이 생길 수 있습니다. 따라서 오라클은 ASH 버퍼를 읽는 세션에 대해서는 래치를 요구하지 않으며 그 때문에 간혹 일관성 없는 잘못된 정보가 나타날 수도 있습니다.
ASH 기능을 이용하면 현재뿐 아니라 과거시점에 발생한 장애 및 성능 저하 원인까지 세션 레벨로 분석할 수 있게 도와줍니다. 오라클 10g부터는 v$active_session_history 정보를 AWR 내에 보관하므로 과거치에 대한 세션 레벨 분석이 가능해졌습니다(SGA를 DMA방식으로 액세스)
1/10만 샘플링해서 저장(문제가 되는 대기 이벤트는 일정간격을 두고 지속적으로 발생하기 때문에 샘플링된 자료만으로도 원인을 찾는데 큰 지장이 없습니다)
v$active_session_history를 조회했을때 정보가 찾아지지 않는다면 이미 AWR에 쓰여진것으로 dba_hist_active_sess_history 뷰를 조회하면 됩니다.
1. AWR 뷰를 이용해 하루 동안의 이벤트 발생현황을 조회해본다. 그래프는 dba_hist_system_event를 이용해 그린 것인데, 08:15~09:15 구간에서 enq: TM - contention 이벤트가 다량 발생한 것이 환인 되었다.
2. dba_hist_active_sess_history를 조회해서 해당 이벤트를 많이 대기한 세션을 확인한다.
3. 블로킹 세션 정보를 통해 dba_hist_active_sess_history를 다시 조회한다.블로킹 세션이 찾아지면 해당 세션이 그 시점에 어떤 작업을 수행 중이었는지 확인한다. sql_id를 이용해 그 당시 SQL과 실행계획까지 확인할 수 있다. v$sql과 v$sql_plan까지 AWR에 저장되기 때문이다.위 사례에서는 블로킹 세션인 Append Mode Insert를 수행하면서 Exclusive 모드 TM Lock에 의한 경합이 발생하고 있었다.
4. program, module, action, client_id 등 애플리케이션 정보를 이용해 관련 프로그램을 찾아 Append 힌트를 제거한다. 그러고 나서,다른 트랜잭션과 동시에 DML이 발생할 수 있는 상황에서는 insert문에 Append 힌트를 사용해서는 안된다는 사실을 개발팀 전체에 공지한다.
ASH Viewer
ASH Viewer는 오라클 인스턴스 액티브 세션 히스토리 데이터 모니터링을 제공합니다.링크를 통해 무료로 오픈소스기반 모니터링 툴을 다운받을 수 있습니다.
최근 ASH Viewer를 통해 실시간으로 Oracle 시스템을 모니터링하며 업무 진행하고 있습니다. V$ACTIVE_SESSION_HISTORY 데이터 기반으로 실시간으로 Oracle 시스템 현황을 모니터링 하는 툴인데요. 아직까지는 익숙치 않지만, 기존에 블로그를 통해 학습해왔던 오라클 시스템 튜닝 용어들을 실제 사용과 함께 눈에 익히고 있는 중입니다.
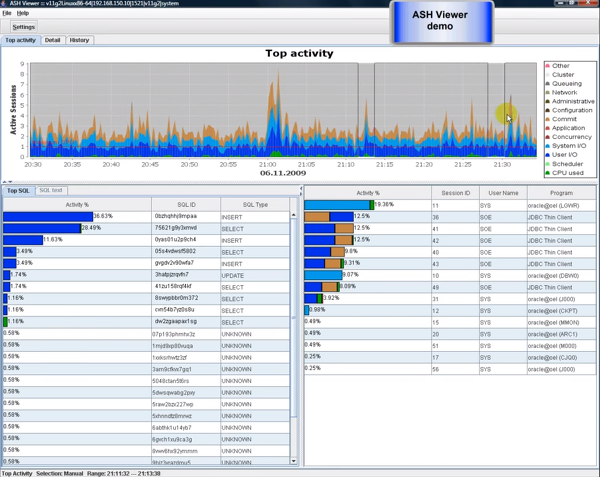
아래는 데모동영상에서 캡쳐한 화면입니다. 실제 Top Activity 화면도 아래와 같았습니다.
Other, Cluster, Queueing, Network, Administrative, Configuration, Commit, Application, Concurrency, System I/O, User I/O, Scheduler, CPU Used등의 항목을 Activice 세션당 사용률에 따라 아래 그래프처럼 표시됩니다. 보고싶은 시간만큼 그래프를 드래그하면 SQL, Session, Program 상세를 확인할 수 있습니다.
Detail 탭을 누르면 Top Activity 항목에 대한 상세 현황 그래프를 확인할 수 있습니다.
JAVA 기반 어플리케이션을 구동하다보면 OOM(Out Of Memory)관련 에러가 발생하는 경우가 종종있습니다. 이럴 경우, JVM 옵션을 통해 관련 부분을 튜닝할 수 있습니다. 위 실행 방법의 Xmx가 그 옵션 중 하나입니다.
JAVA 메모리 구조
- Heap = Eden + Survivor + Old
- Non-Heap = Perm
GC와 Heap 영역의 기본 동작 원리
- gc는 Eden과 ss1을 클리어하고 여전히 유효한 메모리에 대해서는 ss2로 이동시킵니다.
- 그 다음 gc는 Eden과 ss2을 클리어하고 다시 유효한 메모리에 대해서는 ss1로 이동시킵니다.
메모리는 우선, Heap과 Non-Heap으로 나뉩니다.
- Heap영역: new 연산자로 생성된 객체와 배열을 저장하는 영역으로 GC대상이 되는 영역입니다.
Eden: new키워드를 통해서 객체가 처음 생성되는 공간
Survivor: GC가 수행될때 살아있는 객체는 survivor 영역으로 이동
Old: survivor에서 일정시간 참조되는 객체들이 이동되는 공간
- Non-Heap영역: 스택, 클래스 area, method area 등의 head을 제외한 나머지 영역
Permanent:Class 메타정보, Method 메타정보, Static Object, 상수화된 String Object, Class관련 배열 메타정보, JVM 내부 객체와 최적화컴파일러(JIT) 최적화 정보등 포함
XX: MaxPerm Size 옵션 값
XX:MaxPerm Size는 hot-deploy가 있을때 메모리 사용량이 점차 증가하는 부분입니다. 가령 서버에서 PermGen OOM 에러 발생시 이부분의 사이즈를 조절해야 합니다.
JVM Option
-Xms
초기 Heap Size (Init, default 64M)
-Xmx
최대 Heap Size (Max, default 256M)
-XX:PermSize
초기 PermSize
-XX:MaxPermSize
최대 PermSize
-XX:NewSize
최소 new size(객체가 생성되어 저장되는 초기공간의 Size로 Eden+Survivor 영역)
-XX:MaxNewSize
최대 new Size
-XX:SurvivorRatio
New/Survivor영역 비율 (n으로 지정시 Eden: Survivor = 1:n)
-XX:NewRatio
Young Gen과 Old Gen의 비율(n으로 지정시 Young:Old = 1:n)
-XX:+DisableExplicitGC
System.gc() 콜을 무시
-XX:+UseConcMarkSweepGC
표준 gc가 아니나 Perm Gen영역도 gc하는 Concurrent Collector를 사용
-XX:+CMSPermGenSweepingEnabled
Perm gen영역도 GC의 대상이 되도록 지정
-XX:+CMSClassUnloadingEnabled
클래스 데이터도 GC의 대상이 되도록 지정
위에 기본 값을 기준으로 흔하게 일어나는 상황에 대한 조치 방법은 아래와 같습니다.
Hot Deploy 사용으로 재배포가 자주 일어나는 시스템 환경인 경우
1. PermGen 영역의 사이즈를 충분히 늘린다(but 한계 존재)
2. UseConcMarkSweepGC, CMSPermGenSweepingEnabled, CMSClassUnloadingEnabled 등의 옵션으로 PermGen 영역도 GC 수행
OOME, PermGen OOME(Out of Memory Exception) 발생
1. OOME: Xms, Xmx 조정
2. PermGen OOME: XX:PermSize, XX:MaxPermSize 조정
Xmx, Xmx를 동일하게 세팅하는 이유
1. Xms로 init메모리를 잡고, committed 도달할때까지 Used용량이 점차 증가하는데, committed에 도달시 메모리를 추가할 당시 시스템 부하 발생(WAS가 몇 ms가량 멈출 가능성 있음)
2. 메모리 용량은 init < used < committed < max
보통 운영시스템에서 Xms와 Xmx를 동일하게 지정하는 이유는 init와 max사이에서 used 메모리가 committed까지 사용하게 되면, 신규 메모리 공간을 요구하는데 이때 약 1초가량 jvm이 메모리 할당을 멈추는 경우가 생깁니다. 그래서 Xms와 Xmx를 동일하게 주고 메모리를 확보한 상태에서 jvm을 기동시키고는 합니다.
예를 들어, 개발한 배치, 개발자의 임의 작업 등이 잘못 진행되고 있다가 뒤늦게 발견하여 cancel했을 경우라던가 할 때
이를 rollback을 하는 중이지만 UNDO tablespace의 unexpire 영역이 반환되지 않아,
정규 배치 등의 서비스가 실패할 가능성이 있는 시나리오에 대응하려면
다음 쿼리들을 통해 문제를 해결하도록 한다.
Rollback 진행 중인 undo segment를 조회하는 쿼리
parallel rollback 일 경우
select * from v$fast_start_transactions where state='RECOVERING';
serial rollback 일 경우 (x$KTUXE(Kernel Transaction Undo Transaction Entry))
select ktuxesiz from sys.xm$ktuxe where ktuxesta = 'ACTIVE' and KTUXECFL = 'DEAD' ;
Undo tablespace의 사용량은 다음과 같이 확인한다.
col msg format a80 WITH TB AS ( SELECT TABLESPACE_NAME ,(SELECT ROUND(SUM(BLOCKS)*8/1024) FROM DBA_DATA_FILES WHERE TABLESPACE_NAME=A.TABLESPACE_NAME) TOT_MB ,SUM(DECODE(A.STATUS,'ACTIVE' ,SIZE_MB,0)) ACTIVE_MB ,SUM(DECODE(A.STATUS,'UNEXPIRED',SIZE_MB,0)) UNEXPI_MB ,SUM(DECODE(A.STATUS,'EXPIRED' ,SIZE_MB,0)) EXPIRE_MB FROM ( SELECT TABLESPACE_NAME, STATUS, ROUND(SUM(BYTES)/1024/1024) SIZE_MB FROM DBA_UNDO_EXTENTS --WHERE tablespace_name in ( select value from v$parameter where name='undo_tablespace') GROUP BY TABLESPACE_NAME, STATUS ) A GROUP BY TABLESPACE_NAME ) SELECT to_char(sysdate,'HH24:MI:SS')||' '||TABLESPACE_NAME||' : '||round((active_mb+unexpi_mb+expire_mb)/tot_mb*100)|| ' % -> Act('||active_mb||') Unexp('||unexpi_mb||') Exp('||expire_mb||') TOT('||TOT_MB||')' MSG, round(100*(ACTIVE_MB)/TOT_MB,2), round(100*(ACTIVE_MB+UNEXPI_MB)/TOT_MB,2) FROM TB;
현재 진행되고 있는 rollback의 잔여시간은 다음 쿼리로 대충 추산할 수 있다.
set serveroutput on declare l_start number ; l_end number ; r_min number ; begin select ktuxesiz into l_start from sys.xm$ktuxe where ktuxesta = 'ACTIVE' and KTUXECFL = 'DEAD' ; dbms_lock.sleep(60); select ktuxesiz into l_end from sys.xm$ktuxe where ktuxesta = 'ACTIVE' and KTUXECFL = 'DEAD' ; r_min := round(l_end / (l_start - l_end) ) ; dbms_output.put_line('['||to_char(sysdate,'HH24:MI:SS')||'] Remain Time : '|| r_min ||'분 '|| round(r_min/60,2)||'시간 / '||(l_start-l_end)||' blocks done / '|| l_end ||' Total blocks remains' ); end ; /
운영DB에 임시 UNDO Tablespace를 생성한 후, 향후의 트랜잭션들은 이 UNDO tbs를 사용하도록 조치한다.
alter tablespace undotbs2 add datafile '/dev/rdsk/vsp1_000_ra000/dat_000_20G_002';
...
alter tablespace undotbs2 add datafile '/dev/rdsk/vsp1_000_ra000/dat_000_20G_NNN';
alter system set undo_tablespace=undotbs2 ;
이때 UNDO tablespace를 변경하는 것 자체는 금방 수행되므로 긴장하지 않아도 된다.
다만, alert log에 'active transactions found in undo tablespace NN - moved to pending switch-out state 라는 로그가 트랜잭션 당 1 라인씩 계속 발생할 수 있는데, 어떤 사이트의 경우에는 이 메시지가 다량 발생하기도 하였다고 하므로, alert log가 존재하는 path의 가용량을 모니터링하면서 작업 수행하자.
이러한 세션들은 세션에서 commit을 찍고 알아서 종료되길 기다리거나, 아니면 kill하여 처리하면 된다.
UNDO tablespace를 switch 한 후, 이전의 UNDO tbs를 사용하는 채로 commit 되지 않고 남아있는 세션을 찾아본다
select a.usn, a.name, b.status, c.tablespace_name, d.addr, e.sid, e.serial#, e.username, e.program, e.machine, e.osuser from v$rollname a, v$rollstat b, dba_rollback_segs c, v$transaction d, v$session e where a.usn=b.usn and a.name = c.segment_name and a.usn = d.xidusn and d.addr = e.taddr and b.status = 'PENDING OFFLINE';
SYS/+ASM> set line 200 SYS/+ASM> col disk_group for a10 SYS/+ASM> col label for a10 SYS/+ASM> col state for a10 SYS/+ASM> select a.name as disk_group, d.name "Label", a.state 2 from v$asm_disk d, v$asm_diskgroup a 3 where d.group_number=a.group_number 4 order by 2;
DISK_GROUP Label STATE ---------- ---------- ---------- DATA ASM1 MOUNTED FRA FRA1 MOUNTED
2) ASM 내부 살펴보기
2.1 ASM인스턴스에 현재 연결되어 있는 Disk group확인
SYS/+ASM> set line 200 SYS/+ASM> col group_number for 99 SYS/+ASM> col name for a10 SYS/+ASM> col type for a10 SYS/+ASM> col state for a10 SYS/+ASM> select group_number, name, type, state from v$asm_diskgroup;
GROUP_NUMBER NAME TYPE STATE ------------ ---------- ---------- ---------- 1 DATA EXTERN MOUNTED 2 FRA EXTERN MOUNTED
2.2 디스크 그룹별 세부 상세 정보 보기
SYS/+ASM> col group_number for 999 SYS/+ASM> col disk_number for 999 SYS/+ASM> col name for a10 SYS/+ASM> col mount_status for a10 SYS/+ASM> col path for a15 SYS/+ASM> select group_number, disk_number, name, mount_status, path, total_mb 2 from v$asm_disk;
SYS/+ASM> set line 200 SYS/+ASM> set pagesize 50 SYS/+ASM> col group_number for 99 SYS/+ASM> col file_name for 999 SYS/+ASM> col type for a15 SYS/+ASM> select group_number, file_number, round((bytes/1024/1024),1) MB, redundancy, type 2 from v$asm_file;
- Oracle Cluster Repository약자로 cluster의 정보를 담고 있고 윈도우로 말하면 레지스트리의 역할을 하며 RAC상의 모든 노드들에 대한 정보와 모든 자원들에 대한 정보가 저장 되어 있습니다. OCR이 장애가 발생하면 RAC전체가 중단되므로 관리 철저를 요망!!!!
2. 특징
- OCR 디스크의 소유자는 기본적으로 root이지만 경우에 따라서 oracle사용자가 될수 있음
10g까지는 RAC 시작후 ASM instance를 시작하기 때문에 OCR을ASM에 저장할 경우 RAC를 시작할 수 없게 된다. 따라서 OCR, Vote disk는 ASM storage 에 저장하지 않고 raw device 에 저장한다.
Oracle이 권장하는 OCR의 최소 크기는 100MB이다.
Vote disk
각 노드들의 장애 여부를 구분하기 위해서 사용하는 일종의 출석부 이다. RAC는 여러개의 인스턴스 노드들로 구성되어 있으면 각 노드들이 문제가 있는지 없는지를 실시간으로 파악하고 있어야 한다.
RAC를 구성하는 프로세스 중에서 cssd 라는 프로세스가 각 노드 들이 정상적으로 작동하고 있는지 매 초 마다 interconnet를 통해 매 초마다 heartbit를 보내고 각 노드는 그에 대한 응답을 보낸다. 각 노드들은 cssd가 보내는 heartbit에 대하여 자신이 정상작동하고 있음을 vote disk에 기록해두고 있다.
1차 cssd 는 Heartbit를 보내고 노드의 응답을 기다린다. 응답이 없을 경우
2차 cssd는 votedisk에 가서 확인해본다.
노드의 표시가 없다면 노드에 장애가 생겼다고 판단하고 해당 노드를 cluster에서 제외하고 재부팅하게된다.
참고로 11g RAC 부터는 OCR 과 Vote disk 를 모두 ASM Storage 에 저장 할 수 있습니다. 그리고 11g 부터는 Clusterware 가 Grid Infrastructure 라는 프로그램에 통합이 되어서 Grid 프로그램을 설치하면 자동으로 설치가 됩니다.
OCR은 RAC를 구성하는 정보를 저장하는 저장소라는 것이 있습니다. 이러한 OCR정보는 RAC 환경에서 매우 중요한 관리 항목으로 주기적인 백업을 받아 두어야 합니다. 기본적으로 OCR 백업은 4시간 마다 자동으로 백업이 이루어 지며, 비상 상황을 대비하여 3벌의 백업을 자동으로 유지 관리 합니다.
OCR file은 root 소유로 되며 Oracle Cluster Repository의 약자로 말그대로 Cluster의 정보를 담고 있습니다.
1-2 OCR 수동 백업/복구 절차
ocrconfig -backuploc // 백업 시작
ocrconfig -showbackup // 백업 현황 조회
ocrconfig -restore // 복구(모든 NODE 중지 후 한 NODE씩 작업 진행)
ocrconfig -export // export
ocrconfig -import // import
1-3 CLUSTER를 중단시키고 OCR 정보를 Import 하는 방법
CLUSTER상의 모든 Node를 Shutdown 한 후 Node 한대만을 single-usermode로 올립니다.
ocrconfig -import 명령을 사용하여 import를 수행 합니다.
CLUSTER상의 모든 Node를 Multi-usermode로 구동시킵니다.
1-4 CLUSTER를 중단시키지 않고 OCR 정보를 Import 하는 방법
모든 Node의 initab 파일을 다른 이름으로 COPY 해놓은 후 모든 NODE 상의 initab entries를 Update 하고 CRS 관련 entry를 제거합니다.
모든 Node에서 /etc/init.d/init.crsstop 명령을 사용하여 CRS를 중지 시킵니다.
CLUSTER상의 한 Node에서 ocrconfig -import 명령을 사용하여 OCR export를 수행합니다.
모든 Node에서 originalinitab file을 복원 합니다.
모든 Node에서 /etc/init.d/init.crsstart명령으로 CRS START
/etc/initq 명령을 실행 합니다.
2. Voting
2-1 Votiong 이란?
Oracle 소유로(오라클 설치시 UID) 되며 장애시 어떤 Node를 제거할지 검사하는 용도로 사용 합니다.
OCR과 Voting Disk는 Oracle Cluster component들 입니다. 스토리지에서 OCR, Voting Disk부터 controlfile, datafile등의 순서로 Oracle은 파일들을 체크하면서 읽기 시작 합니다. OCR은 cluster와 cluster 내의 resource의 정보를 담고 있고 Voting Disk는 각 노드의 status를 확인하기 위해 사용 합니다